
四技术背景与行业应用OCR技术支撑护照阅读器的核心是OCR识别引擎tesseract怎么读,需具备高准确率如99%以上和多语言支持能力部分厂商如清华大学人工智能实验室孵化的企业已开发出支持中英混排日韩文藏文等识别的专用SDKtesseract怎么读,远超开源技术如Tesseract的识别率行业认可度护照阅读器因效率提升显著,已被多数高端酒店。
使用 Tesseract 和 Python 矫正文本方向,主要步骤如下导入必要的库pytesseract用于调用 Tesseract OCR 引擎cv2OpenCV用于图像处理numpy用于数值计算读取图像使用 cv2imread 读取图像文件将图像从 BGR 颜色空间转换为 RGB 颜色空间,因为 Tesseract 期望输入为 RGB 格式检测文本方向。
Unsupported OS for Tesseract path configuration#34printpytesseractget_languages注意事项路径准确性确保路径指向正确的Tesseract可执行文件,否则会引发 FileNotFoundError环境变量配置替代方案在系统或用户环境变量中设置 TESSERACT_PATH,指向Tesseract路径在代码中读取该变量需确保IDE。
TesseractNotFoundError print#34错误Tesseract未找到,请检查安装或路径配置#34 except Exception as e printf#34处理图片时出错e#34关键注意事项路径格式使用正斜杠分隔路径如homepiimagejpg路径大小写敏感,需与实际文件系统一致语言包安装未。
具有简单易用的表格识别功能具有TXTRTFHTM和XLS多种输出格式,并有所见即所得的版面还原功能新增打开与识别PDF文件功能,支持文字型PDF的直接转换和图像型PDF的OCR识别,既可以采用OCR的方式将PDF文件转换为可编辑文档,也可以采用格式转换的方式直接转换文字型PDF文件为RTF文件或文本文件。
如Madeleine L#39Engle时间的皱纹涉及爱因斯坦相对论普朗克“量子学说”及超时空挪移tesseract概念儒勒·凡尔纳科幻三部曲之海底两万里环游地球八十天包含地理常识海洋生物知识阅读文学作品还能间接拓宽历史社会神话等背景知识,如tesseract怎么读了不起的盖茨比反映20世纪20年代社会状况,古希腊。
Visual Studio高效编程技巧集封面深度技术实践NET Bios数据读写教程详细讲解如何通过NET读取写入Bios数据如序列号SN,涉及底层硬件交互及安全注意事项地址cnblogs kybs0p43 C#调用Tesseract C++ API记录分享在C#项目中集成Tesseract OCR引擎的完整流程,包括环境配置API调用及错误处理。
手写体识别Tesseract对手写体支持较差,建议训练专用模型或使用商业API完整代码示例import cv2import pytesseractfrom PIL import Imagedef ocr_with_preprocessingimage_path, lang=#39eng#39 # 读取图像 image = cv2imreadimage_path # 预处理灰度化 + 二值化 gray = cv2cvtColo。
Tesseract OCRTesseract OCR是一款开源的OCR光学字符识别引擎,最初由惠普HP实验室研发,后来经过谷歌Google的改进和优化它具有强大的文本识别能力,不仅可以识别常见的英文字符,还能对数字进行准确识别由于其开源的特性,开发者可以根据具体需求对其进行定制和扩展,以适应不同的应用场景在。
在Vue3组件中,通过调用Tesseract Worker的接口,实现图片中字符的识别功能注意确保图片路径和格式正确,以便Tesseract能够正确读取和处理打包和分发在完成集成和测试后,可以使用Electron的打包工具将项目打包为可执行文件注意在打包过程中,确保所有必要的资源都被正确包含在内重点内容 解决CSP。
三使用Read PDF With OCR和Tesseract OCR进行中文文本提取 添加控件在UiPath项目中,添加“Read PDF With OCR”和“Tesseract OCR”两个控件这两个控件将用于读取PDF文件并进行OCR识别配置Tesseract OCRTesseract OCR支持多种语言,包括中文但是,默认情况下,Tes。
可以使用OCR技术来扫描文字,并通过拼音转换工具将这些文字转换成拼音OCR技术能够通过扫描和识别图像中的文字,将其转换为可编辑的文本现在市面上有许多成熟的OCR引擎,如Google的Tesseract OCRABBYY FineReader等,它们能够高效地识别印刷或手写的文字当OCR技术识别出图像中的文字后,我们可以利用拼音。
NDLOCR适合识别古籍中复杂排版的OCR项目,支持日本语言识别,并能备注汉字读音删除非字符在广告区域读取字符它还采取了一些有趣的举措,如根据年龄提高识别准确性OCRmyPDF基于TesseractOCR开发的项目,专门用于将扫描或图像文件中的文本转换为可编辑的PDF文档它能够将识别到的文本信息作为透明。
在按键精灵中,用于辅助识字的插件有多种选择,以下是一些可能好用的插件推荐1 OCR文字识别插件 Tesseract OCR这是一个开源且功能强大的OCR引擎,支持多种语言的文字识别通过按键精灵调用Tesseract OCR,您可以轻松地将图片中的文字识别并提取出来,适用于各种需要文字识别的场景2 屏幕截图插件。
2 读数识别阶段#8226 针对检测到的表盘区域,提取指针位置或数字字符如滚轮式燃气表的数字#8226 若为指针式表结合指针相对刻度的角度计算数值若为数字式表可将检测到的数字区域裁剪后,用OCR模型如PaddleOCRTesseract识别,或直接在YOLOv8中加入OCR分支如YOLOv8+CRNN3。
4 扩展建议结合OCR优化若需同时提取单号和姓名,可改用OCR如PaddleOCR或Tesseract识别截图中的文字,但需处理排版复杂性问题自动化反馈将单号与收件人信息整合后,可通过邮件或短信API自动发送物流信息,进一步提升效率总结通过Python的pyzbar和opencv模块,可快速实现快递单号的批量识别,尤其适合。
二软件与算法调整1 选择轻量化模型优先使用轻量级OCR算法如Tesseract的精简版PaddleOCR的超轻量模型,减少模型参数量和计算复杂度2 开启硬件加速在OCR软件中启用GPU加速如CUDAOpenCL或多线程处理,充分利用硬件资源3 优化参数设置降低识别精度阈值如调整置信度下限减少。
 mask怎么读音发音英语怎么说
mask怎么读音发音英语怎么说 母牛英文bull和ox
母牛英文bull和ox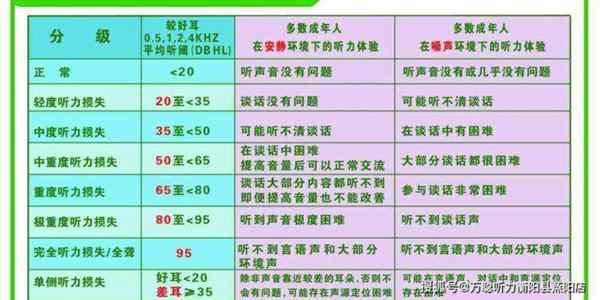 英语六级听力频率是多少赫兹
英语六级听力频率是多少赫兹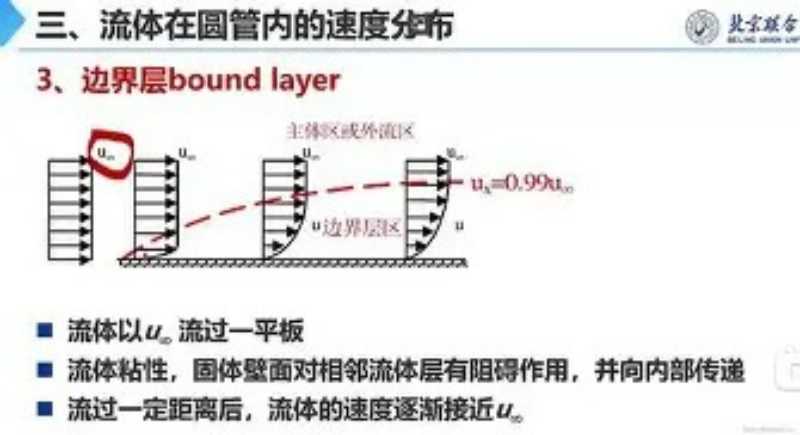 racial的用法及短语
racial的用法及短语