
Python123答案可以找python123网站的地址Python123 编程更简单北京理工大学搭建的学习python 的网站可以边学边练习百度python123网站,知乎之类的软件都可以搜索到答案python123 答案,二老鼠打洞,来自计算机的问候任意数量参数,自定义幂函数,来自计算机的问候多参函数,编写函数输出自除数,最大素数,求数列前npython123 答案,二老鼠打洞,来。
python123根据键盘输入输出字典的值python123根据键盘输入输出字典的值#python123网站?以输入3个值和键为dicpython123网站?=?for?i?in?range0,3key?=?inputquot输入建quotval?=?inputquot输入值quota=#391#39#39yi,222,333#39,#394#39#39si,555,666#39,检索到1时,让str=‘yi’list1=#392#39,#392#39,#392#39。
使用 Python 的 Requests 库抓取网页数据时,若遇到无法在 Response 中获取正确内容的问题,通常由编码设置不当或请求模拟不足导致,可通过以下方法针对性解决一编码问题解决方案当直接打印 responsetext 显示乱码或非预期内容时,可能是 Requests 未自动识别响应编码需手动设置 responseencoding 属性。
使用Python爬虫抓取号码的核心步骤包括确定目标获取内容提取数据存储结果,以下是具体实现方法及代码示例方法一正则表达式提取号码适用于从纯文本或HTML中直接匹配固定格式的号码如身份证等import reimport requests# 1 获取目标网页HTMLurl = #34。
python是一门动态语言,它可以在运行时声明和使用变量,同时它也是一种强类型的语言,这一点有别于PHP,python会提供强制类型转换的方法,与java类似,但是PHP的话编译器会自动识别python123网站你所运用的变量到底是哪种类型 注意 ‘123’可以通过int来转化成123,但是别的非数字字符串就不可 同时python。
spider – hao123网站爬虫 简介以hao123为入口,滚动爬取外链,收集网址并记录信息GitHub地址。
注意事项并非所有网站提供 APIAPI 可能需认证如 API KeyOAuth,需遵守使用条款示例PHP$api_url = #34#34$ch = curl_init$api_urlcurl_setopt$ch, CURLOPT_RETURNTRANSFER, truecurl_setopt$ch, CURLOPT_。
 工程师职称报名入口在哪
工程师职称报名入口在哪 大学交换生是怎么回事
大学交换生是怎么回事 笔友用英语说
笔友用英语说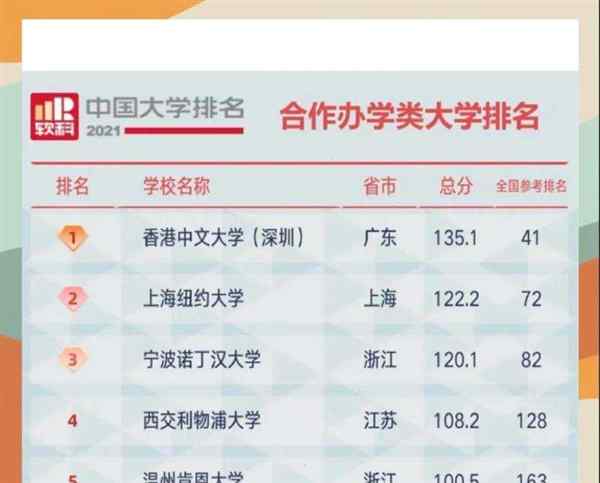 中外合作大学排名一览表及分数线
中外合作大学排名一览表及分数线 浙江工业大学录取分数线多少
浙江工业大学录取分数线多少